Нова технологія від Google на основі AI зможе покращити роздільну здатність зображень на 16 разів
 Розробники Google представили нову технологію, яка може значно покращити якість стартової картини. AI Popixelly відтворює відсутні ділянки навіть на стисненому зображенні.
Розробники Google представили нову технологію, яка може значно покращити якість стартової картини. AI Popixelly відтворює відсутні ділянки навіть на стисненому зображенні. Команда мозку розвивається. Вони представили два алгоритми для отримання фотографії. Перший -SR3, він здатний масштабувати зображення за допомогою повторного переробки. Збільшення дозволу відбувається через запозичення відсутніх фрагментів від гауссового шуму. Навчання AI побудовано на методах спотворення картини та подальшої зворотної процедури.
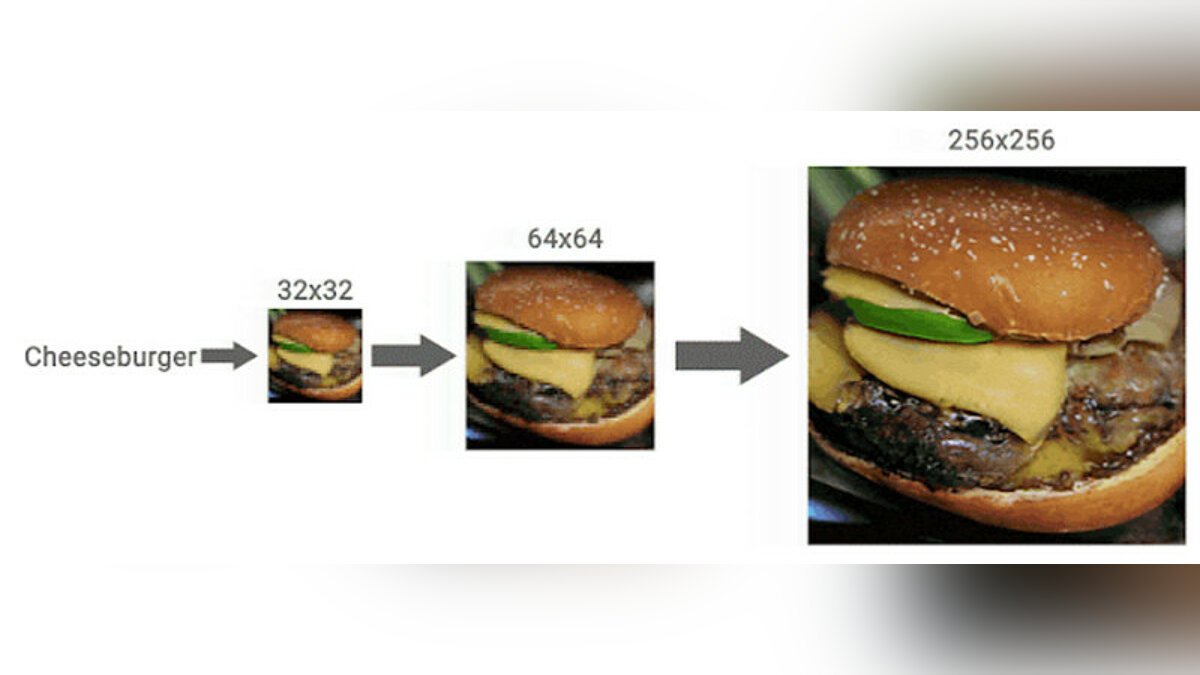
Ще одна дифузна технологія-CDM. У ньому штучний інтелект навчався з використанням мільйонів зображень у високій роздільній здатності з бази даних Imagenet. Масштабування тут поетапно. Отже, початкове зображення 32 × 32 пікселів покращується до 64 × 64, а потім - до 256 × 256 (8 разів). Оригінальний 64 × 64 може бути збільшений таким чином до 1024 × 1024, тобто 16 разів.
За словами розробників, нова технологія показує найкращі результати порівняно з сучасними методами масштабування, використовуючи Biggan-Deep та VQ-VAE-2 AI.
Команда не надала більш детальної інформації про представлену технологію. Кінцевий термін випуску комерційної версії розробки невідомий.